想让机器不仅听懂你在说什么,还能精确知道每个字是在哪一秒说出的吗?
在语音技术的世界里,让机器“听懂”内容(语音识别)只是第一步。在很多场景下,我们还需要知道每个字、每个词是在音频的哪个时间点说出来的。这就是语音强制对齐技术的核心任务。
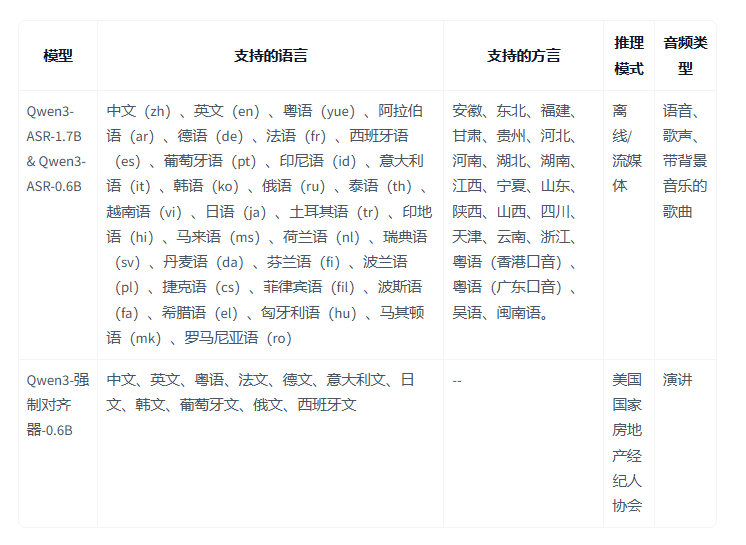
今天,我们要一起探索的是一个强大而轻量的工具——Qwen3-ForcedAligner-0.6B 模型。它来自通义千问团队,能以 6 亿参数(0.6B)的规模,高效地完成音频与文本的精准“同步”。
什么是语音强制对齐?为什么需要它?
想象一下,你有一堂45分钟讲座的录音和它的文字稿。你想做一个“点击文字就能跳到对应视频位置”的交互功能。强制对齐模型就是实现这个功能的“幕后英雄”。它能自动计算出文字稿中每一个句子、每一个词语,甚至每一个字,在音频文件中开始的毫秒级时间点。
这项技术有许多重要的应用:
-
有声书/字幕制作:自动生成带时间轴的精准字幕。
-
语言学习:帮助学习者精确跟读,对比自己的发音位置。
-
语音数据标注:为训练更高级的语音模型(如语音合成TTS)自动生成高精度的时间标注。
-
教学分析:分析课堂录音中教师与学生的发言时长、互动频率等。
Qwen3-ForcedAligner-0.6B:一款专注对齐的专家模型
Qwen3-ForcedAligner-0.6B 正是为了解决上述任务而专门设计和训练的。虽然它的“出身”通义千问以强大的大语言模型闻名,但这款模型是一个专注于语音领域的“专家”。
它的核心特点可以概括为:
-
精准对齐:核心功能是将输入的音频和对应的文本,在时间线上精确地对应起来。
-
轻量高效:0.6B(约6亿)的参数规模,使其对计算资源的要求相对友好。它可以在较好的消费级GPU上运行,甚至在优化后可能部署在一些边缘设备上,推理速度也很快。
-
专注任务:它不追求“什么都会”,而是将“强制对齐”这一件事做到极致。
-
易于集成:作为 Hugging Face 生态系统中的一员,它可以很方便地通过
transformers库加载和使用。
手把手教你使用 Qwen3-ForcedAligner
下面,我们将通过一个简单的示例,展示如何使用这个模型。通常,这类模型的输入是一个音频文件和与之对应的文本。
准备工作
首先,确保你的 Python 环境中安装了必要的库:
pip install transformers torchaudio librosa soundfile
第一步:加载模型和处理器
模型通常会搭配一个专用的处理器(Processor),它负责将音频和文本处理成模型需要的格式。
from transformers import AutoModelForCTC, AutoProcessor import torchaudio import torch # 模型名称 model_name = "Qwen/Qwen3-ForcedAligner-0.6B" # 加载处理器(包含特征提取器和分词器) processor = AutoProcessor.from_pretrained(model_name) # 加载模型 model = AutoModelForCTC.from_pretrained(model_name)
第二步:准备输入数据
假设我们有一个名为 my_speech.wav 的音频文件,以及它的文本转录 "今天的天气真好"。
# 加载音频文件,强制对齐器通常需要原始的波形数组和采样率 speech_array, sampling_rate = torchaudio.load("my_speech.wav") # 重要:检查采样率,如果与模型预训练的不一致,需要进行重采样 # 模型的采样率通常是16kHz,我们可以通过processor的feature_extractor查看 expected_sr = processor.feature_extractor.sampling_rate if sampling_rate != expected_sr: resampler = torchaudio.transforms.Resample(sampling_rate, expected_sr) speech_array = resampler(speech_array) sampling_rate = expected_sr # 将音频转换为单声道(如果为立体声) if speech_array.shape[0] > 1: speech_array = torch.mean(speech_array, dim=0, keepdim=True) # 输入的转录文本 transcription = "今天的天气真好"
第三步:进行对齐推理
这是最核心的一步。模型的处理流程通常是:
-
将音频通过声学模型处理成一系列帧的概率分布。
-
将文本通过分词器转换成令牌(Token)序列。
-
使用一种称为维特比解码(Viterbi Algorithm)的动态规划算法,找出音频帧与文本令牌之间最有可能的对应路径,从而计算出每个令牌的时间点。
虽然底层的 model 和 processor 已经封装了大部分复杂性,但具体调用 forced_align 这类方法的方式可能因模型而异。一个典型的使用逻辑如下:
# 使用处理器同时处理音频和文本,为模型准备输入 # 这里会进行必要的填充或截断 inputs = processor( audio=speech_array.squeeze().numpy(), sampling_rate=sampling_rate, text=transcription, return_tensors="pt" ) # 模型前向传播 with torch.no_grad(): outputs = model(**inputs) # 从模型输出中提取对齐信息 # 注意:outputs的具体结构需要查看模型文档,可能包含logits和强制对齐的辅助输出 # 假设模型返回了每个token的时间戳(这只是其中一种可能) logits = outputs.logits # --- 这里需要根据模型的具体输出来处理 --- # 一般流程:获取最优路径(令牌ID序列),然后将令牌ID映射回文本,并利用帧率和步长计算时间。 # 为了方便演示,我们假设有一个函数可以完成这个复杂过程 def extract_timestamps(emission, tokens, processor): # 这是一个伪代码示例,实际需要使用维特比解码 # emission: 声学模型的输出 (时间帧数, 词汇表大小) # tokens: 目标文本对应的令牌ID列表 # 返回每个令牌的开始和结束时间列表 pass # 假设我们获得了每个字的开始和结束时间 # word_timestamps = extract_timestamps(...)
请务必查阅模型的官方文档,了解 processor 和 model 提供的具体接口。一些模型可能已经内置了 processor.align_with_transcription() 之类的便捷方法。
结语
Qwen3-ForcedAligner-0.6B 为语音和文本之间的精准“同步”提供了一个强大且易用的解决方案。无论你是想优化字幕制作流程,还是为语音应用开发新功能,这款轻量级的专家模型都值得一试。
我们鼓励你前往 Hugging Face 的模型页面,仔细阅读其提供的 Model Card 和示例代码(如果已发布),这是掌握其用法的黄金标准。
希望这篇介绍能为你打开一扇探索语音技术的新窗口。如果你在使用过程中有任何心得或问题,欢迎在评论区留言交流!
评论(0)