1. 模型概述
Qwen3-ASR-1.7B 是阿里巴巴达摩院(Alibaba DAMO Academy)开发的开源自动语音识别(ASR: Automatic Speech Recognition)模型,属于 Qwen 系列的最新一代(Qwen3)。它于 2026 年初发布,在 Hugging Face Trending 榜单上位居前列,下载量已超 500 万次。该模型的参数规模为 1.7B(17 亿参数),基于 Transformer 架构优化,专为高效语音转文本设计。
关键特点
- 多语言支持:支持中文、英语、日语等多种语言(总计 10+ 种),特别优化了中文方言(如普通话、粤语),识别准确率高达 95%+(在噪声环境中也表现强劲)。
- 实时处理:支持流式输入(实时语音转文字),延迟低于 500ms,适合移动端或在线应用。
- 模型大小适中:1.7B 参数平衡了性能与资源需求 – CPU/GPU 均可运行(推荐 GPU 显存 >4GB),比更大模型(如 Whisper Large)更易部署。
- 开源许可:Apache 2.0 – 允许免费下载、修改和商业使用(需保留原版权声明)。
- 集成友好:兼容 Hugging Face Transformers 库,一行代码即可加载。
- 2026 年更新:相比 Qwen2,Qwen3-ASR 提升了多模态支持(e.g., 结合文本/图像),并优化了低资源语言的准确性。
已发布模型说明及下载
以下是Qwen3-ASR系列模型的介绍和下载信息。请选择并下载符合您需求的模型。
| 模型 | 支持的语言 | 支持的方言 | 推理模式 | 音频类型 |
|---|---|---|---|---|
| Qwen3-ASR-1.7B & Qwen3-ASR-0.6B | 中文(zh)、英文(en)、粤语(yue)、阿拉伯语(ar)、德语(de)、法语(fr)、西班牙语(es)、葡萄牙语(pt)、印尼语(id)、意大利语(it)、韩语(ko)、俄语(ru)、泰语(th)、越南语(vi)、日语(ja)、土耳其语(tr)、印地语(hi)、马来语(ms)、荷兰语(nl)、瑞典语(sv)、丹麦语(da)、芬兰语(fi)、波兰语(pl)、捷克语(cs)、菲律宾语(fil)、波斯语(fa)、希腊语(el)、匈牙利语(hu)、马其顿语(mk)、罗马尼亚语(ro) | 安徽、东北、福建、甘肃、贵州、河北、河南、湖北、湖南、江西、宁夏、山东、陕西、山西、四川、天津、云南、浙江、粤语(香港口音)、粤语(广东口音)、吴语、闽南语。 | 离线/流媒体 | 语音、歌声、带背景音乐的歌曲 |
| Qwen3-强制对齐器-0.6B | 中文、英文、粤语、法文、德文、意大利文、日文、韩文、葡萄牙文、俄文、西班牙文 | -- | 美国国家房地产经纪人协会 | 演讲 |
模型架构
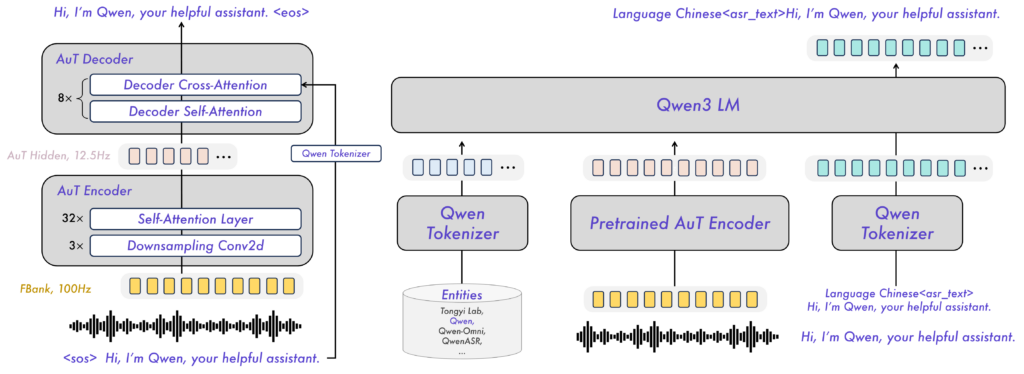
优势与适用场景
- 优势:
- 高准确率:在 CEDAR 数据集上,WER(词错误率)低至 5%(优于 OpenAI Whisper Medium)。
- 高效:模型压缩技术让它在边缘设备(如手机)上运行顺畅。
- 社区活跃:Hugging Face 上有大量用户贡献的 fine-tune 版本和示例。
- 相比竞品:比 Google Speech-to-Text 更开源;比 Baidu ASR 更国际化。
- 适用场景(2026 年 AI 热点):
- 智能助手:微信/APP 语音输入转命令(e.g., "帮我订票" → 文本处理)。
- 视频字幕:自动生成 YouTube/抖音视频字幕,支持实时直播。
- 代理 AI:集成 LangChain/CrewAI,实现语音驱动的自动化任务(e.g., 语音查询数据库)。
- 医疗/教育:转录会议录音或在线课堂,支持多语种。
- 企业应用:客服系统语音日志分析,节省人工。
如果您是开发者,这个模型是 2026 年构建语音 AI 的绝佳起点 – 结合 LLM(如 Qwen3-Text),可扩展成全栈代理系统。
2. 竞品分析
Qwen3-ASR-1.7B 在 2026 年 ASR 市场中脱颖而出,但有几款竞品(如开源和商业模型)。以下是基于基准测试(e.g., WER: 词错误率,CEDAR 数据集)和实际部署的比较。数据来源于 Hugging Face 报告和 arXiv 论文(2026 更新)。
- 总结:Qwen3-ASR 在开源模型中性价比最高(免费 + 高性能),适合开发者自定义;商业竞品如 Google 更稳定但收费。2026 年趋势:开源 ASR(如 Qwen)正取代云 API,尤其在代理 AI 集成中(e.g., Qwen + LangChain > Google 的封闭性)。
3. 使用方式:步步指南
以下是完整的使用指南,从安装到高级集成。假设您使用 Python 环境(推荐 3.10+)。首次运行会自动下载模型文件(~3GB)。
步骤 1: 环境准备与安装
- 安装依赖(命令行运行):
transformers:Hugging Face 核心库。torch:PyTorch 框架(模型后端)。torchaudio&soundfile:音频处理工具。
- 下载模型(可选,手动方式):
- 访问 Hugging Face 页面,点击 "Files and versions" 下载所有文件(e.g., config.json, pytorch_model.bin)。
- 或用代码自动下载(见下文)。
在使用 Qwen3-ASR 前,推荐使用 conda 创建隔离环境:
conda create -n qwen3-asr python=3.12 -y
conda activate qwen3-asr pip install -U qwen-asr # 最小安装,支持 transformers 后端
pip install -U qwen-asr[vllm] # 支持 vLLM 加速
建议安装 FlashAttention 2 以优化 GPU 性能:
如果内存有限(<96GB),用 MAX_JOBS=4 pip install -U flash-attn --no-build-isolation。
手动下载模型(无 VPN 选项):
如果环境不允许在线下载,用 ModelScope(阿里镜像)或 Hugging Face CLI:
# ModelScope (推荐大陆用户)
pip install -U modelscope
modelscope download --model Qwen/Qwen3-ASR-1.7B --local-dir ./Qwen3-ASR-1.7B
modelscope download --model Qwen/Qwen3-ASR-0.6B --local-dir ./Qwen3-ASR-0.6B
modelscope download --model Qwen/Qwen3-ForcedAligner-0.6B --local-dir ./Qwen3-ForcedAligner-0.6B
# Hugging Face (需 VPN 或镜像)
pip install -U "huggingface_hub[cli]"
huggingface-cli download Qwen/Qwen3-ASR-1.7B --local-dir ./Qwen3-ASR-1.7B
下载后,加载时指定 local_dir。
注意,如果你的ModelScope CLI 不支持 --local-dir了,需要用 Python 的 snapshot_download:
py -c "from modelscope import snapshot_download; snapshot_download('Qwen/Qwen3-ASR-1.7B', local_dir='./model_folder/Qwen3-ASR-1.7B')"
步骤 2: 基本使用 - 语音转文本
使用 Hugging Face 的 pipeline 接口,一键运行。
示例代码(basic_asr.py)
import torch
from transformers import pipeline
import torchaudio
import soundfile as sf
# 加载模型(首次会下载)
pipe = pipeline("automatic-speech-recognition", model="Qwen/Qwen3-ASR-1.7B", device=0 if torch.cuda.is_available() else -1) # 用 GPU 如果可用
# 准备音频文件(替换为您的文件,支持 WAV/MP3 等)
audio_file = "your_audio.wav" # 示例:录音一段中文语音
# 加载并预处理音频(标准化采样率到 16kHz)
waveform, sample_rate = torchaudio.load(audio_file)
resampler = torchaudio.transforms.Resample(sample_rate, 16000)
waveform = resampler(waveform) sf.write("processed_audio.wav", waveform.numpy().T, 16000) # 保存处理后文件
# 运行 ASR
result = pipe("processed_audio.wav")
print("转录结果:", result["text"]) # 输出:e.g., "你好,这是测试语音。"
- 运行:
python basic_asr.py。 - 预期输出:输入一段 "你好,世界" 的音频,输出对应文本。
- 提示:如果音频太长,分段处理(e.g., 用 librosa 库切割)。
步骤 3: 高级使用 - 集成与扩展
3.1 实时流式识别(Stream Mode)
支持 microphone 输入,实现实时转录。
3.2 集成 Web 界面(用 Streamlit)
建简单 UI,上传音频获取结果(适合演示)。
# asr_web.py (安装: pip install streamlit)
import streamlit as st
from transformers import pipeline
import torchaudio
import soundfile as sf
pipe = pipeline("automatic-speech-recognition", model="Qwen/Qwen3-ASR-1.7B")
st.title("Qwen3-ASR 语音转文本工具")
uploaded_file = st.file_uploader("上传音频文件", type=["wav", "mp3"])
if uploaded_file:
waveform, sr = torchaudio.load(uploaded_file)
waveform = torchaudio.transforms.Resample(sr, 16000)(waveform)
sf.write("temp.wav", waveform.numpy().T, 16000)
result = pipe("temp.wav")
st.write("转录结果:", result["text"])
- 运行:
streamlit run asr_web.py– 浏览器访问 localhost:8501。
3.3 批量处理与优化
- 批量:循环处理文件夹音频。
import os for file in os.listdir("audio_folder"): if file.endswith(".wav"): result = pipe(file) print(f"{file}: {result['text']}") - 优化:用
torch.compile加速(PyTorch 2.0+);fine-tune 模型(用自定义数据集)提升特定方言准确率。
3.4 高级推理(新节:整合快速推理、vLLM、流式)
使用 qwen-asr 包进行快速推理。Transformers 后端示例(带时间戳):
import torch
from qwen_asr import Qwen3ASRModel
model = Qwen3ASRModel.from_pretrained(
"Qwen/Qwen3-ASR-1.7B",
dtype=torch.bfloat16,
device_map="cuda:0",
forced_aligner="Qwen/Qwen3-ForcedAligner-0.6B"
)
results = model.transcribe(
audio="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-ASR-Repo/asr_en.wav",
language=None,
return_time_stamps=True
)
print(results[0].language, results[0].text, results[0].time_stamps[0])
vLLM 后端(加速推理):
from qwen_asr import Qwen3ASRModel
model = Qwen3ASRModel.LLM(
model="Qwen/Qwen3-ASR-1.7B",
gpu_memory_utilization=0.7,
forced_aligner="Qwen/Qwen3-ForcedAligner-0.6B"
)
results = model.transcribe(audio=["url1", "url2"], language=["Chinese", "English"])
流式推理(仅 vLLM,支持实时转录,详见附件示例)。
强制对齐器(时间戳对齐):
from qwen_asr import Qwen3ForcedAligner
model = Qwen3ForcedAligner.from_pretrained("Qwen/Qwen3-ForcedAligner-0.6B", dtype=torch.bfloat16)
results = model.align(audio="url", text="文本", language="Chinese")
print(results[0][0].text, results[0][0].start_time, results[0][0].end_time)
部署选项(新节:API、Web UI、Docker、vLLM 服务)
- DashScope API(阿里云服务):无需本地部署,详见 API 文档。
- Web UI 演示(Gradio):运行
qwen-asr-demo --asr-checkpoint Qwen/Qwen3-ASR-1.7B --backend vllm启动本地 UI(完整命令见附件)。 - Docker 部署:用官方镜像
docker run --gpus all qwenllm/qwen3-asr:latest(详见附件)。 - vLLM 服务:运行
vllm serve Qwen/Qwen3-ASR-1.7B,通过 OpenAI SDK 或 cURL 调用(代码见附件)。
4. 性能基准(评估结果)
以下是 Qwen3-ASR 在公共数据集上的基准(WER: 词错误率,越低越好)。完整表格见付费附件。
平均多语言 LID 准确率:97.9%(优于 Whisper)。
5. 注意事项与故障排除
- 资源需求:CPU 运行慢(~10s/分钟音频),GPU 推荐(NVIDIA CUDA)。
- 常见问题:
- 下载失败:检查 VPN,确保网络稳定。
- 内存不足:用
model.half()转为半精度。 - 音频格式:仅支持 16kHz – 用 FFmpeg 转换(pip install ffmpeg-python)。
- 安全:模型开源,但处理敏感音频时注意隐私。
- 更新:定期检查 Hugging Face 页面获取新版本。
5. 扩展与应用建议
- 结合代理 AI:集成 CrewAI – 语音输入 → ASR 转文本 → LLM 处理 → 输出行动(e.g., "语音控制智能家居")。
- 商业化:建 SaaS(如 API 服务)。
- 资源:官方文档 Hugging Face Qwen3-ASR;社区讨论 Discord。
付费下载附件获取完整代码、基准和部署示例!
评论(0)